Error Handlers: Architectural Limitations for Data Integrity
In Mendix, the Error Handler mechanism is available to handle logic errors that otherwise are unhandled. While not intended by Mendix, it sometimes is viewed as a suitable defense mechanism for maintaining Data Integrity.
While effective for technical recovery, this mechanism falls short when managing business-level data integrity, as evaluated in the sections below.
2.1. The Error handling main strategies
To balance stability with precision, developers can implement custom error handling at the activity or block level using three main strategies:
- Rollback (Default): Stops the process and reverts all changes to ensure a clean state.
- Custom Without Rollback: Catches the error while preserving changes made prior to the error, ideal for logging or audit trailing without losing progress.
- Continue: Skips the failing step, which requires careful design to ensure subsequent logic doesn't rely on corrupted data.
2.2. The Error handling sub-strategies
To refine your error-handling strategy, you must consider how the flow concludes and how you manually manage state:
- End-node selection: A regular “End Event” allows the microflow execution to proceed normally, while an “Error Event” re-throws the error. If this handler exists in the top-microflow of the microflow hierarchy the choice of End Node determines the final state of the local transaction. A standard End Event allows the transaction to commit if the error was caught and resolved within the flow. Conversely, an Error Event terminates the current flow and the platform triggers a full database rollback. Note that raising an unhandled exception is not affecting the state of the objects in the Client Cache.
- Adding custom rollback: Within a "Custom without Rollback" error path, the database transaction remains open and active. To prevent "dirty" data from persisting or synchronizing to the client, developers can use the “Rollback Object” action. This allows for selective reversion of sensitive objects, such as a pending invoice, to their last committed state. This is a critical tool for maintaining data integrity when the developer intends for the flow to continue (e.g., to log the error in a separate persistent entity) without carrying over the failed mutations.
2.3. Adding Error-handling to the Menditect Testability Framework
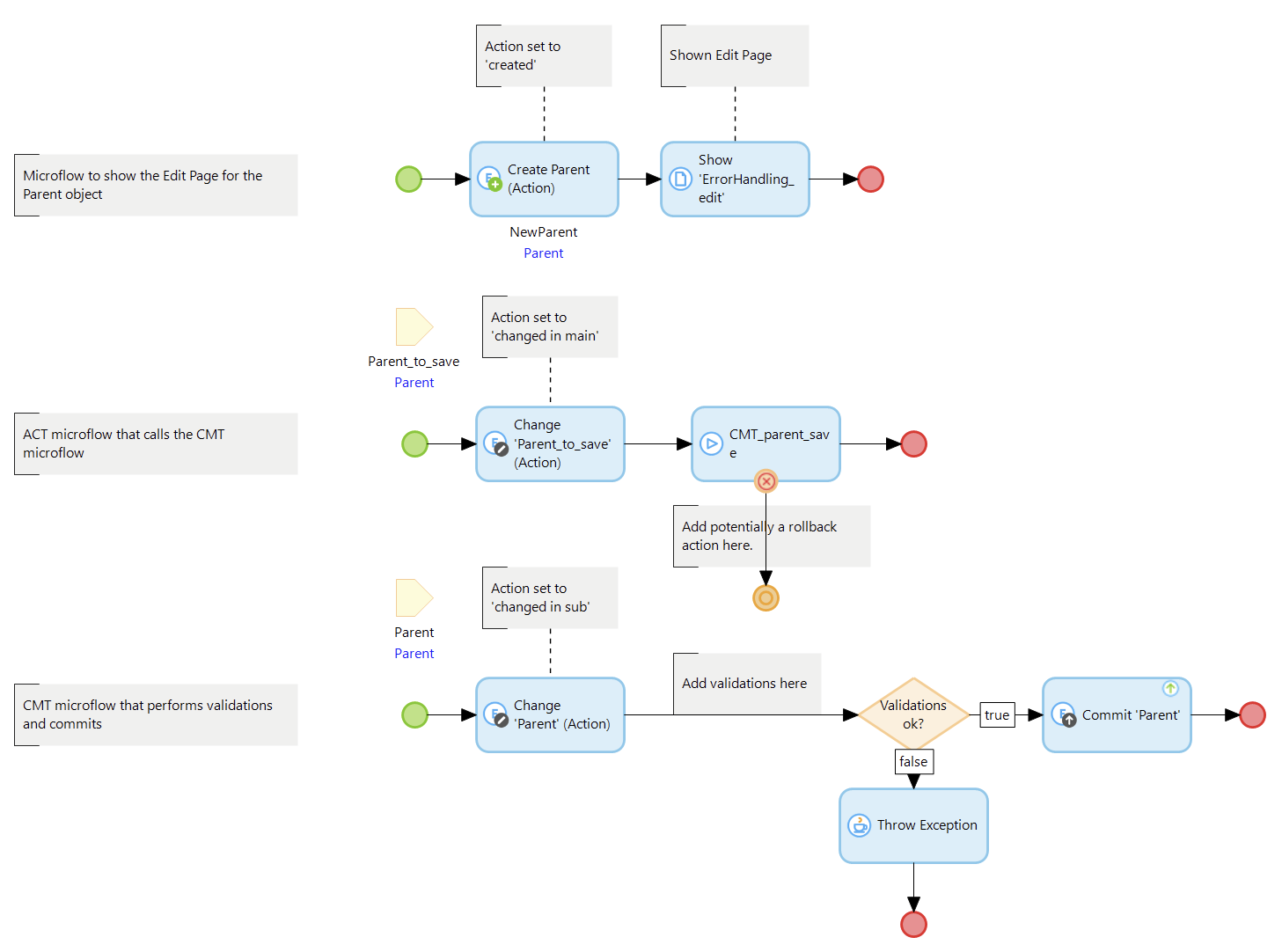
In an atttempt to apply error-handling as a strategy to enforce Data Integrity in the Menditect Testability Framework the most obvious place to implement that is the CMT microflow pattern. This microflow serves as the central point for starting the evaluation of business rules and commiting data if validations are successfull executed.
In order to use error-handling for this purpose, an error should be raised if one or more business rules are violated and a custom error handler should be added to the CMT microflow to automate the reversal of all modifications performed within the call hierarchy.
The picture below shows a simple framework implementation where a ‘Parent’ object is created, validated and stored. If a validation is violated, an error is thrown and handled with an error handler. The ‘Change Parent’ actions are added to find out the actual state in the testbed.
In the remainder of this document, the previously explained error handling main- and sub-strategies are evaluated to find out if one of the configurations is useful for Data Integrity.
2.4. Evaluation of the Error Handling Mechanism for Data Integrity
To determine the efficacy of the Mendix Error Handling Mechanism as a tool for enforcing Data Integrity, we evaluate the impact of each strategy on the global system state (Database vs. Runtime Memory vs. Client Cache).
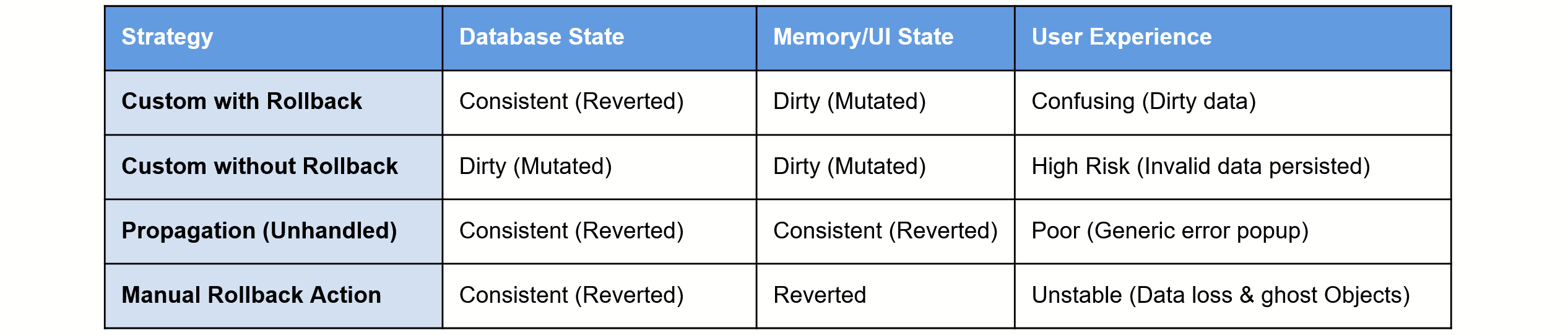
2.4.1. Error Handler 'With Rollback'
This strategy creates a “state mismatch”. While it reverts the Database Transaction Buffer, it fails to revert the Microflow Context (Runtime memory) to the state it had at the start of the transaction. This "dirty" state is then synchronized to the Client Cache, causing the UI to display invalid data even though the database remains consistent.
2.4.2. Error Handler 'Without Rollback'
This configuration is intended for scenarios where a developer performs manual corrective actions. However, from a Data Integrity perspective, it is a high-risk "Open State" scenario. It leaves the the Microflow Context in a ‘dirty’ state. And, unless the error handler is added to a commit action, the Database Transaction Buffer is in a ‘dirty’ state as well.
If this mechanism is applied, the developer is forced to implement logic that decontaminate every affected object.
2.4.3. Re-throwing the Error (Native Rollback)
Re-throwing an error will cause a full ACID-compliant rollback of both the database and the Microflow Context memory without synchronizing the client cache, provided that the error remain uncatched within the microflow hierarcy.
While this is the only native method to guarantee a perfectly clean state, it creates a structural barrier for the UX because validation feedback is suppressed leaving the user without information about which specific fields need to be corrected and why the action is not allowed.
Understandable this is done for security reasons, but it this behavior prevents the use of it as a reliable data-integrity mechanism.
2.4.4. Adding a Manual Rollback Action (Forced Rollback)
In this scenario, a manual “Rollback Object” action is added to the error-handling path to revert the object to its last committed state. However, this implementation introduces two critical side effects that compromise the user experience.
First, it forces a synchronization of the Client Cache to this reverted state, regardless of whether the ‘Refresh in client’ toggle is enabled. Furthermore, if the object was created before the current transaction but not yet committed, the rollback destroys the in-memory instance, causing the user interface to lose its data source and become unresponsive. This destabilizing behavior remains identical across both "With Rollback" and "Without Rollback" error handler configurations making this configuration unusable for data integrity.
2.5. Conclusion on Error Handlers
Standard error handling mechanisms prove inadequate for robust data validation due to two fundamental architectural conflicts:
- Feedback Suppression: If an error is re-thrown, the database reverts correctly, but the user is blinded. The platform suppresses specific validation feedback and "pink" field highlighting, replacing helpful guidance with a generic system exception.
- State Synchronization: If the error is handled to preserve the UI, the platform forces a synchronization of "dirty" or "destroyed" server-side states to the Client Cache. This either contaminates the browser with invalid data or renders the interface unresponsive.
Ultimately, error handlers are a technical safety net, not a business logic tool. To achieve true data integrity without sacrificing user experience, developers must look beyond these native traps and adopt patterns that isolate validation from the transaction commit cycle.
In summary